Project Description:

Patrolling means the act of walking or traveling around an area, at regular intervals, to protect or supervise it. Given a graph, the patrolling task refers to continuously visiting all the graph nodes to minimize the time lag between two visits. We have to design an automated patrolling system with multiple agents to monitor a given environment with nodes of interest of varying priorities. A group of students is working on the simulation part of this project, provided by the DRDO, India. They will do the hardware aspect of this project. This project's main objective is to prevent the innocent lives of many soldiers who are at the borders working at their top edge and died while patrolling manually. So, instead of them, an autonomous car will do this task and keep a keen observation of the enemies' movement.
Project Report
My Learnings & Contribution till date:
Proposed a novel technique for Multi-Robot Patrolling using IoT devices for a secured, decentralised decision making and robust solution against device failures.
Developed a local, reactive, decentralized algorithm (MRPP-IoT) to minimize Graph Idleness with IoT devices at Junctions as the decision-making units.
Analyzed patrolling performance of MRPP-IoT algorithm based on an extensive and systematic set of simulations carried out on SUMO (a traffic simulator).
Comparison of the MRPP-IoT algorithm with two states of the art strategies - Conscientious Reactive as well as Reactive with Flags 2 [8] demonstrate the possibility of a decentralised solution for MRPP that maintains the uniformity of patrolling even during device failures.
Applied Conscientious Reactive architecture with emergent coordination strategy for reducing idleness using Traci library in a realistic traffic simulator - Simulation of Urban MObility (SUMO)
This project gave me an insight into Reinforcement Learning in my second year. Created an algorithm for decision making based on RL Techniques and tested it on platforms like MIT DeepTraffic Simulator and Unity ML-Agents. This algorithm helps in making decisions like accelerating, decelerating, left & right based on the surrounding.
During my learning period, I applied the RL method using ROS and gazebo and simulated a self-balancing inverse pendulum, which learns to balance itself from previous experience
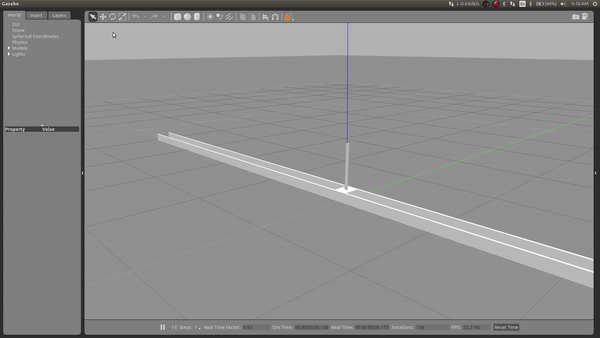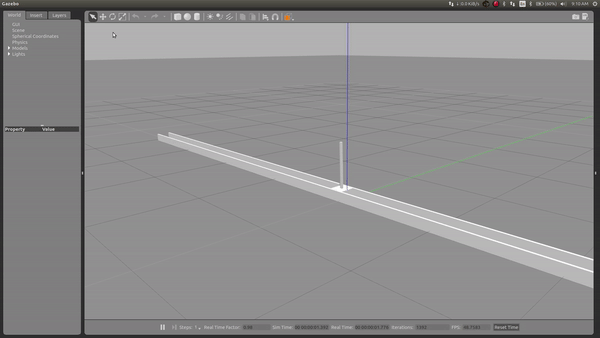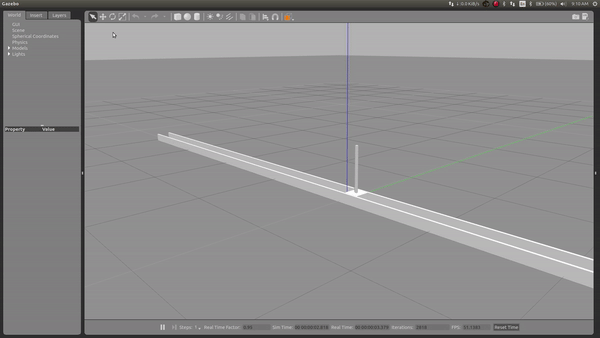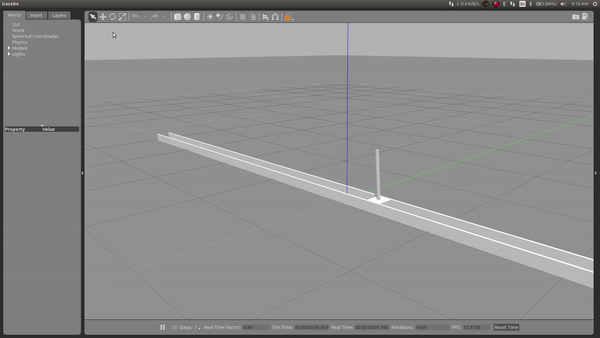 Simulation in gazebo
Simulation in gazebo Results
Results